The newest benchmark assessments of chip pace in coaching neural networks was launched on Tuesday by the MLCommons, an trade consortium. As in previous years, Nvidia scored prime marks throughout the board within the MLPerf assessments.
With opponents Google, Graphcore and Superior Micro Gadgets not submitting entries this time round, Nvidia’s dominance throughout all eight assessments was full.
Additionally: AI will change software program growth in huge methods
Nevertheless, Intel’s Habana enterprise introduced significant competitors with its Guadi2 chip, and the corporate pledges to beat Nvidia’s top-of-the-line H100 GPU by this fall.
The benchmark check, Coaching model 3.0, reviews what number of minutes it takes to tune the neural “weights”, or parameters, till the pc program achieves a required minimal accuracy on a given activity, a course of known as “coaching” a neural community.
Together with coaching on server computer systems, MLCommons launched a companion benchmark check, MLPerf Tiny model 1.1, which measures coaching efficiency on very-low-powered units.
The principle Coaching 3.0 check, which totals eight separate duties, information the time to tune a neural community by having its settings refined in a number of experiments. It’s one half of neural community efficiency, the opposite half being so-called inference, the place the completed neural community makes predictions because it receives new knowledge. Inference is roofed in separate releases from MLCommons.
Additionally: Nvidia, Dell, and Qualcomm pace up AI ends in newest benchmark assessments
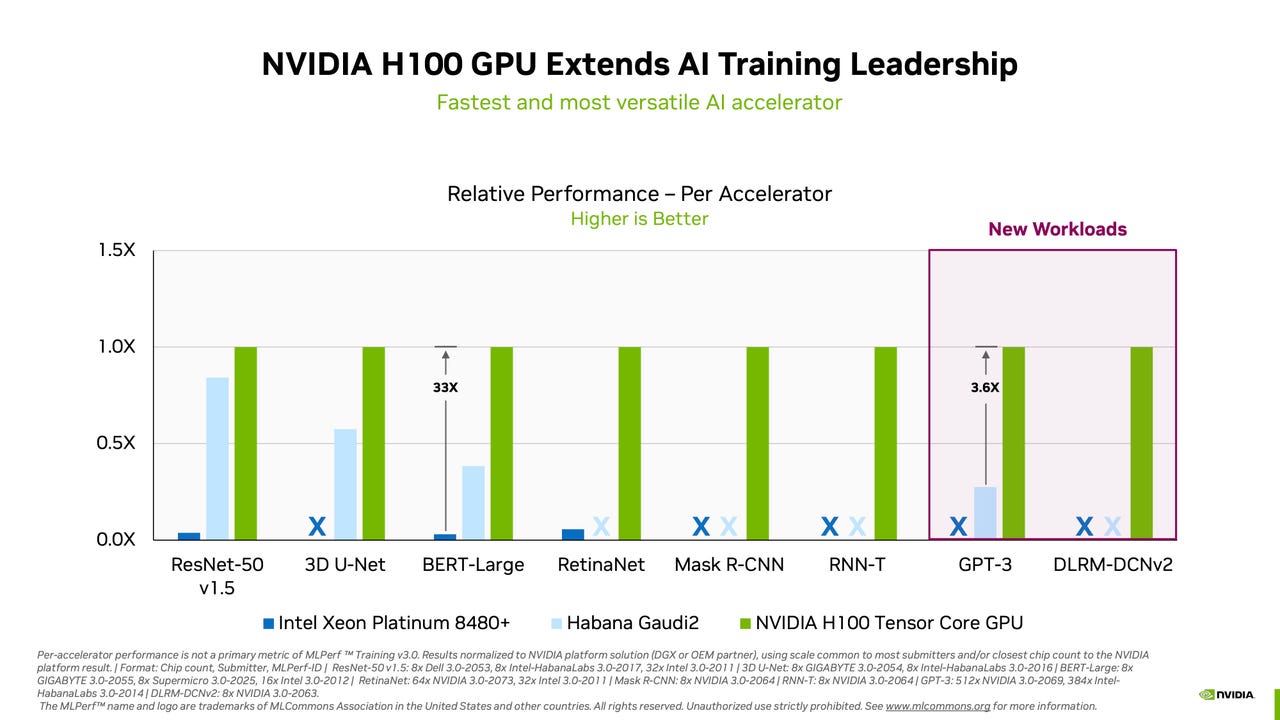
Nvidia took the highest spot in all eight assessments, with the bottom time to coach. Two new duties have been added. One is testing the GPT-3 massive language mannequin (LLM) made by OpenAI. Generative AI utilizing LLMS has grow to be a craze as a result of recognition of OpenAI’s ChatGPT program, which is constructed upon the identical LLM. Within the GPT-3 activity, Nvidia took the highest spot with a system it assembled with the assistance of associate CoreWeave, which rents cloud-based cases of Nvidia GPUs.
The Nvidia-CoreWeave system took just below eleven minutes to coach utilizing an information set referred to as the Colossal Cleaned Frequent Crawl. That system made use of 896 Intel Xeon processors and three,584 Nvidia H100 GPUs. The system carried out the duties utilizing Nvidia’s NeMO framework for generative AI.
The coaching occurs on a portion of the complete GPT-3 coaching, utilizing the “massive” model of GPT-3, with 175 billon parameters. MLCommons restricts the check to 0.4% of the complete GPT-3 coaching in an effort to preserve the runtime affordable for submitters.
Additionally new this time round was an expanded model of the recommender engines which might be in style for issues resembling product search and social media suggestions. MLCommons changed the coaching knowledge set that had been used, which was a one-terabyte knowledge set, with a four-terabyte knowledge set referred to as the Criteo 4TB multi-hot. MLCommons determined to make the improve as a result of the smaller knowledge set was turning into out of date.
“Manufacturing advice fashions are growing in scale — in measurement, compute, and reminiscence operations,” famous the group.
The one vendor of AI chips to compete towards Nvidia was Intel’s Habana, which submitted 5 entries with its Gaudi2 accelerator chip, plus one entry submitted by laptop maker SuperMicro utilizing Habana’s chip. These programs collectively submitted in 4 of the eight duties. In each case, the Habana programs got here in far under the highest Nvidia programs. For instance, within the check to coach Google’s BERT neural community on Wikipedia knowledge to reply questions, Habana got here in fifth place, taking two minutes to finish the coaching versus eight seconds for a 3,072-GPU Nvidia-CoreWeave machine.
Nevertheless, Intel’s Jordan Plawner, head of AI merchandise, famous in an interview with ZDNET that for comparable programs, the distinction in time between Habana and Nvidia is shut sufficient it might be negligible to many corporations.
For instance, on the BERT Wikipedia check, an 8-part Habana system, with two companion Intel Xeon processors, got here in at simply over 14 minutes to coach. That end result was higher than two dozen different submissions, many with double the variety of Nvidia A100 GPUs.
Additionally: To measure ultra-low energy AI, MLPerf will get a TinyML benchmark
“We invite everybody to take a look at the 8-device machines,” mentioned Plawner. “Now we have a substantial value benefit with Gaudi2, the place we’re priced just like a equally spec’d A100, supplying you with extra coaching per greenback.”
Plawner famous that not solely is the Gaudi2 in a position to beat some comparable configurations of Nvidia A100, however the Gaudi2 runs with a slight handicap. Nvidia submitted their MLPerf entries utilizing an information format to coach referred to as “FP-8,” for floating level, 8-bit, whereas Habana used an alternate strategy referred to as BF-16, for B-float, 16-bit. The upper arithmetic precision of the BF-16 hampers the coaching considerably when it comes to time to finish.
Later this 12 months, mentioned Plawner, Gaudi2 shall be utilizing FP-8, which he mentioned will enable for larger efficiency. It can even enable Habana to beat Nvidia’s newer H100 system on efficiency, he predicted.
“The trade wants another” to Nvidia, mentioned Plawner. Prospects, whereas historically reluctant to modify from the trusted model, at the moment are being pushed by a sudden tightness within the provide of Nvidia’s components. CEO Jensen Huang mentioned final month that Nvidia is having a tough time filling demand for H100 GPUs.
“Now they’re motivated,” Plawner informed ZDNET of consumers pissed off by lack of Nvidia provide.
“That is what we’re listening to from them, that they’ve issues they wish to do tomorrow, that the CEO is mandating, they usually can not do it as a result of they can not get GPUs, interval.”
“Belief me, they’re making excess of they’re spending [on generative AI]. If they will put 50 individuals on a Gaudi venture to actually get the identical time to coach, if the reply is, I’ve no GPUs, and I am ready, or, I’ve Guadi2, and I can launch my new service tomorrow, they’ll go purchase Gaudi2s to launch their new service.”
Intel is the world’s second-largest manufacturing facility for chips, or, “fab”, after Taiwan Semiconductor, famous Plawner, which supplies the corporate a capability to manage its personal provide.
Additionally: These mushroom-based chips may energy your units
Though Nvidia builds multi-thousand-GPU programs to take the highest rating, Habana is able to the identical, mentioned Plawner. “Intel is constructing a mutli-thousand Guadi2 cluster internally,” he mentioned, with the implicit suggestion that such a machine could possibly be an entry in a future MLPerf spherical.
Tuesday’s outcomes are the second quarter in a row for the coaching check wherein not a single different chip maker confirmed a prime rating towards Nvidia.
A 12 months in the past, Google cut up the highest rating with Nvidia due to its TPU chip. However Google did not present up in November of final 12 months, and was once more absent this time. And startup Graphcore has additionally dropped out of the operating, specializing in its enterprise quite than exhibiting off check outcomes.
In a cellphone dialog, MLCommons director David Kanter, requested by ZDNET in regards to the no-show by opponents, remarked, “The extra events that take part, the higher.”
Google didn’t reply to an inquiry from ZDNET at press time asking why the corporate didn’t take part this time round. Superior Micro Gadgets, which competes with Nvidia on GPUs, additionally didn’t reply to a request for remark.
Additionally: These are my 5 favourite AI instruments for work
AMD did, nonetheless, have its CPU chips represented in programs that competed. Nevertheless, in a shocking flip of occasions, each single profitable Nvidia system used Intel Xeon CPUs because the host processor. Within the year-earlier outcomes, all eight profitable entries, whether or not from Nvidia or Google, have been programs utilizing AMD’s EPYC server processors. The change reveals that Intel has managed to recoup some misplaced floor in server processors with this 12 months’s launch of Sapphire Rapids.
Regardless of the absence of Google and Graphcore, the check continues to draw new system makers making submissions. This time round, first-time submitters included CoreWeave, but additionally IEI and Quanta Cloud Know-how.
Unleash the Energy of AI with ChatGPT. Our weblog supplies in-depth protection of ChatGPT AI expertise, together with newest developments and sensible purposes.
Go to our web site at https://chatgptoai.com/ to be taught extra.