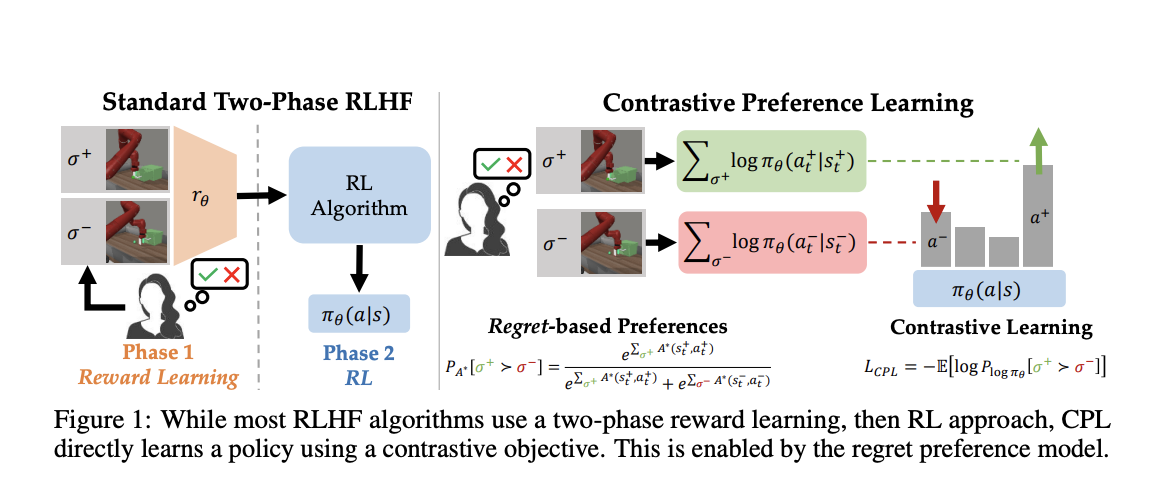
Home/Stanford and UT Austin Researchers Propose Contrastive Preference Learning (CPL): A Simple Reinforcement Learning RL-Free Method for RLHF that Works with Arbitrary MDPs and off-Policy Data/Stanford and UT Austin Researchers Propose Contrastive Preference Learning (CPL): Stanford and UT Austin Researchers Propose Contrastive Preference Learning (CPL):