TikTok proprietor ByteDance’s “Self-Managed Reminiscence system” can attain into an information financial institution of tons of of turns of dialogue, and hundreds of characters, to offer any language mannequin capabilities superior to that of ChatGPT to reply questions on previous occasions. ByteDance
Whenever you kind issues into the immediate of a generative synthetic intelligence (AI) program equivalent to ChatGPT, this system provides you a response primarily based not simply on what you have typed, but in addition all of the belongings you’ve typed earlier than.
You’ll be able to consider that chat historical past as a kind of reminiscence. But it surely’s not enough, in response to researchers at a number of establishments, who’re making an attempt to endow generative AI with one thing extra like an organized reminiscence that may increase what it produces.
Additionally: The way to use ChatGPT: All the pieces it’s worthwhile to know
A paper printed this month by researcher Weizhi Wang from College of California at Santa Barbara, and collaborators from Microsoft, titled “Augmenting Language Fashions with Lengthy-Time period Reminiscence”, and posted on the arXiv pre-print server, provides a brand new element to language fashions.
The issue is ChatGPT and comparable packages cannot absorb sufficient textual content in anyone second to have a really lengthy context for issues.
As Wang and crew observe, “the enter size restrict of present LLMs prevents them from generalizing to real-world eventualities the place the aptitude of processing long-form data past a fix-sized session is essential.”
OpenAI’s GPT-3, for instance, takes maximal enter of two,000 tokens, that means, characters or phrases. You’ll be able to’t feed this system a 5,000-word article, say, or a 70,000-word novel.
Additionally: This new expertise may blow away GPT-4 and the whole lot prefer it
It is attainable to maintain increasing the enter “window,” however that runs right into a thorny computing downside. The eye operation — the important device of all giant language packages, together with ChatGPT and GPT-4 — has “quadratic” computational complexity (see the “time complexity” of computing). That complexity means the period of time it takes for ChatGPT to provide a solution will increase because the sq. of the quantity of knowledge it’s fed as enter. Growing the window balloons the compute wanted.
And so some students, notice Wang and crew, have already tried to provide you with a crude reminiscence. Yuhuai Wu and colleagues at Google final 12 months launched what they name the Memorizing Transformer, which shops a duplicate of earlier solutions that it could in future draw upon. That course of lets it function on 65,000 tokens at a time.
However Wang and crew notice the information can develop into “stale”. The method of coaching the Reminiscence Transformer makes some issues in reminiscence develop into out of sync with the neural community as its neural weights, or, parameters, are up to date.
Wang and crew’s resolution, referred to as “Language Fashions Augmented with Lengthy-Time period Reminiscence”, or LongMem, makes use of a conventional giant language mannequin that does two issues. Because it scrutinizes enter, it shops a few of it within the reminiscence financial institution. It additionally passes the output of each present immediate to a second neural community, referred to as the SideNet.
Additionally: How I tricked ChatGPT into telling me lies
The SideNet, which can also be a language mannequin, similar to the primary community, is tasked with evaluating the present immediate typed by an individual to the contents of reminiscence to see if there is a related match. The SideNet, not like the Reminiscence Transformer, will be educated by itself aside from the principle language mannequin. That approach, it will get higher and higher at selecting out contents of reminiscence that will not be stale.
Wang and crew run exams to check LongMem to each the Memorizing Transformer and to OpenAI’s GPT-2 language mannequin. In addition they evaluate LongMem to reported outcomes from the literature for different language fashions, together with the 175-billion parameter GPT-3.
They use duties primarily based on three datasets that contain summarizing very lengthy texts, together with entire articles and textbooks: Challenge Gutenberg, the arXiv file server, and ChapterBreak.
To provide you an thought of the size of these duties, ChapterBreak, launched final 12 months by Simeng Solar and colleagues on the College of Massachusetts Amherst, takes entire books and exams a language mannequin to see if, given one chapter as enter, it could precisely determine from a number of candidate passages which one is the beginning of the following chapter. Such a job “requires a wealthy understanding of long-range dependencies”, equivalent to modifications in place and time of occasions, and strategies together with “analepsis”, the place, “the following chapter is a ‘flashback’ to an earlier level within the narrative.”
Additionally: AI is extra more likely to trigger world doom than local weather change, in response to an AI skilled
And it includes processing tens and even tons of of hundreds of tokens.
When Solar and crew ran these ChapterBreak exams, they reported final 12 months, the dominant language fashions “struggled”. For instance, the big GPT-3 was proper solely 28% of the time.
However the LongMem program “surprisingly” beat all the usual language fashions, Wang and crew report, together with GPT-3, delivering a state-of-the-art rating of 40.5%, even though LongMem has solely about 600 million neural parameters, far fewer than the 175 billion of GPT-3.
“The substantial enhancements on these datasets display that LONGMEM can comprehend previous long-context in cached reminiscence to properly full the language modeling in direction of future inputs,” write Wang and crew.
The Microsoft work echoes latest analysis at ByteDance, the mum or dad of social media app TikTok.
In a paper posted in April on arXiv, titled “Unleashing Infinite-Size Enter Capability for Massive-scale Language Fashions with Self-Managed Reminiscence System”, researcher Xinnian Liang of ByteDance and colleagues developed an add-on program that provides any giant language mannequin the power to retailer very lengthy sequences of stuff talked about.
Additionally: AI will change software program growth in huge methods, says MongoDB CTO
In apply, they contend, this system can dramatically enhance a program’s skill to position every new immediate in context and thereby make applicable statements in response — even higher than ChatGPT.
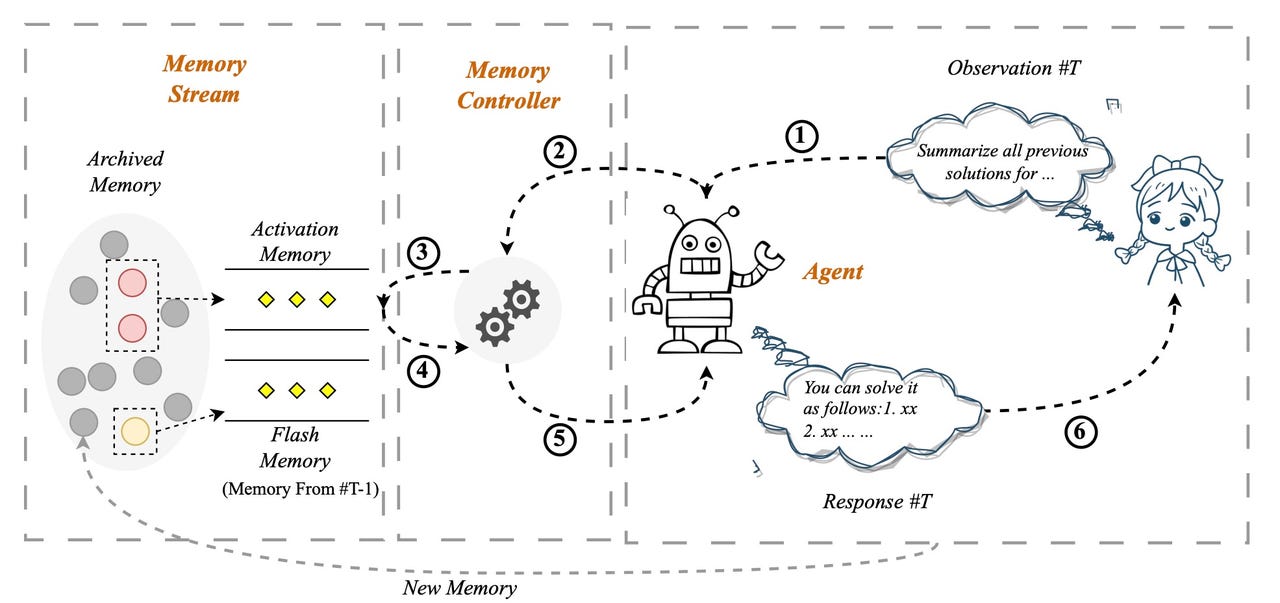
Within the “Self-Managed Reminiscence system”, because it’s referred to as, or SCM, the enter a consumer varieties on the immediate is evaluated by a reminiscence controller to see whether or not it requires dipping into an archival reminiscence system referred to as the reminiscence stream, which comprises all of the previous interactions between the consumer and this system. It is quite like Wang and crew’s SideNet and accompanying reminiscence financial institution.
If reminiscence is required, that assortment of previous enter is accessed through a vector database device equivalent to Pinecone. The consumer’s enter is a question, and it is matched for relevance towards what’s within the database.
Some consumer queries do not require reminiscence, equivalent to “Inform me a joke”, which is a random request that any language mannequin can deal with. However a consumer immediate equivalent to, “Do you keep in mind the conclusion we made final week on the health diets?” is the sort of factor that requires entry to previous chat materials.
In a neat twist, the consumer immediate, and the reminiscence it retrieves, are mixed, in what the paper calls “enter fusion” — and it’s that mixed textual content that turns into the precise enter to the language mannequin on which it generates its response.
Additionally: This new AI system can learn minds precisely about half the time
The top result’s that the SCM can high ChatGPT in duties that contain a reference again to tons of of turns earlier in a dialogue, write Liang and crew. They linked their SCM to a model of GPT-3, referred to as text-davinci-003, and examined the way it carried out with the identical enter in comparison with ChatGPT.
In a single collection of greater than 100 turns, consisting of 4,000 tokens, when the human prompts the machine to recall the hobbies of the individual mentioned on the outset of the session, “the SCM system gives an correct response to the question, demonstrating distinctive memory-enhanced capabilities,” they write, whereas, “in distinction, it seems that ChatGPT was distracted by a substantial quantity of irrelevant historic information.”
The work may also summarize hundreds of phrases of lengthy texts, equivalent to reviews. It does so by iteratively summarizing the textual content, which implies storing the primary abstract within the reminiscence stream, after which creating the following abstract together with the earlier abstract, and so forth.
The SCM may also make giant language fashions that are not chat bots behave like chat bots. “Experimental outcomes present that our SCM system allows LLMs, which aren’t optimized for multi-turn dialogue, to realize multi-turn dialogue capabilities which might be similar to ChatGPT,” they write.
Each the Microsoft and the TikTok work will be considered extending the unique intention of language fashions. Earlier than ChatGPT, and its predecessor, Google’s Transformer, pure language duties had been usually carried out by what are referred to as recurrent neural networks, or RNNs. A recurrent neural community is a sort of algorithm that may return to earlier enter information to be able to evaluate it to the present enter.
Additionally: GPT-4: A brand new capability for providing illicit recommendation and displaying ‘dangerous emergent behaviors’
The Transformer and LLMs equivalent to ChatGPT changed RNNs with the easier method — consideration. Consideration robotically compares the whole lot typed to the whole lot typed earlier than, in order that the previous is all the time being introduced into play.
The Microsoft and TikTok analysis work, subsequently, merely extends consideration with algorithms which might be explicitly crafted to recall parts of the previous in a extra organized vogue.
The addition of reminiscence is such a primary adjustment, it is more likely to develop into a regular facet of enormous language fashions in future, making it way more frequent for packages to have the ability to make connections to previous materials, equivalent to chat historical past, or to handle the entire textual content of very lengthy works.
Unleash the Energy of AI with ChatGPT. Our weblog gives in-depth protection of ChatGPT AI expertise, together with newest developments and sensible purposes.
Go to our web site at https://chatgptoai.com/ to study extra.