Harness the Potential of AI Tools with ChatGPT. Our blog offers comprehensive insights into the world of AI technology, showcasing the latest advancements and practical applications facilitated by ChatGPT’s intelligent capabilities.
The capacity of a model to use inputs at inference time to modify its behavior without updating its weights to tackle problems that were not present during training is known as in-context learning or ICL. Neural network architectures, particularly created and trained for few-shot knowledge the ability to learn a desired behavior from a small number of examples, were the first to exhibit this capability. For the model to perform well on the training set, it had to remember exemplar-label mappings from context to make predictions in the future. In these circumstances, training meant rearranging the labels corresponding to input exemplars on each “episode.” Novel exemplar-label mappings were supplied at test time, and the network’s task was to categorize query exemplars using these.
ICL research evolved as a result of the transformer’s development. It was noted that the authors did not specifically try to encourage it through the training aim or data; rather, the transformer-based language model GPT-3 demonstrated ICL after being trained auto-regressively at a suitable size. Since then, a substantial amount of research has examined or documented instances of ICL. Due to these convincing discoveries, emergent capabilities in massive neural networks have been the subject of study. However, recent research has demonstrated that training transformers only sometimes result in ICL. Researchers discovered that emergent ICL in transformers is significantly influenced by certain linguistic data characteristics, such as burstiness and its highly skewed distribution.
The researchers from UCL and Google Deepmind discovered that transformers typically resorted to in-weight learning (IWL) when trained on data lacking these characteristics. Instead of using freshly supplied in-context information, the transformer in the IWL regime uses data that is stored in the model’s weights. Crucially, ICL and IWL seem to be at odds with one another; ICL seems to emerge more easily when training data is bursty, that is, when objects appear in clusters rather than randomly—and has a high number of tokens or classes. It is essential to conduct controlled investigations using established data-generating distributions to understand the ICL phenomena in transformers better.
Simultaneously, an auxiliary corpus of research examines the emergence of gigantic models trained directly on organic web-scale data, concluding that remarkable features like ICL are more likely to arise in big models trained on a greater amount of data. Nonetheless, the dependence on large models presents significant pragmatic obstacles, including quick innovation, energy-efficient training in low-resource environments, and deployment efficiency. As a result, a substantial body of research has concentrated on developing smaller transformer models that may provide equivalent performance, including emergent ICL. Currently, the preferred method for developing compact yet effective converters is overtraining. These tiny models compute budget and are trained on more data—possibly repeatedly—than what scaling rules need.
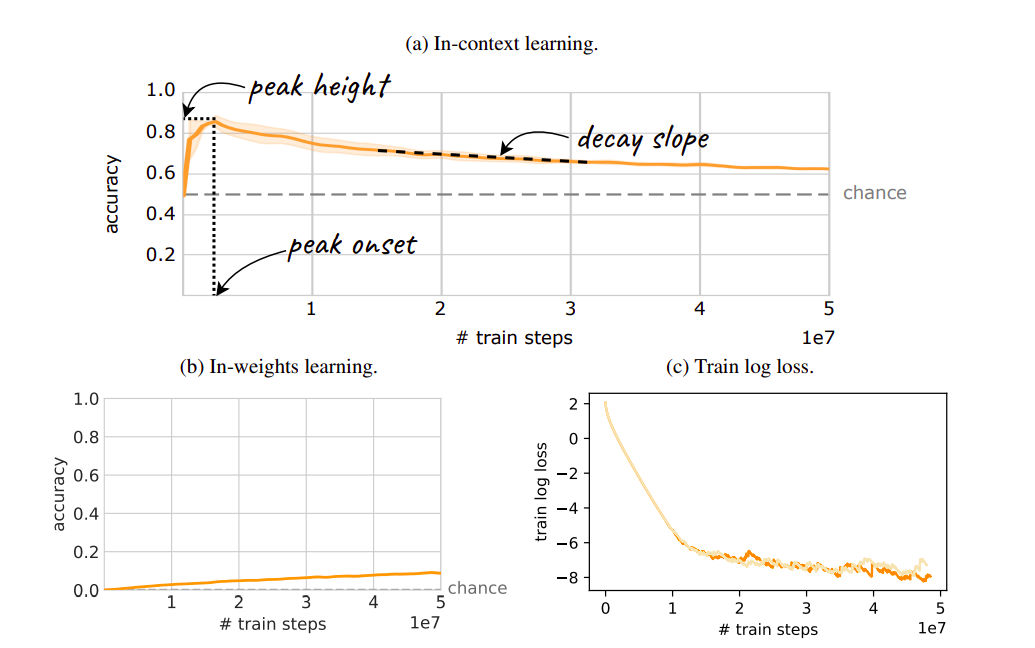
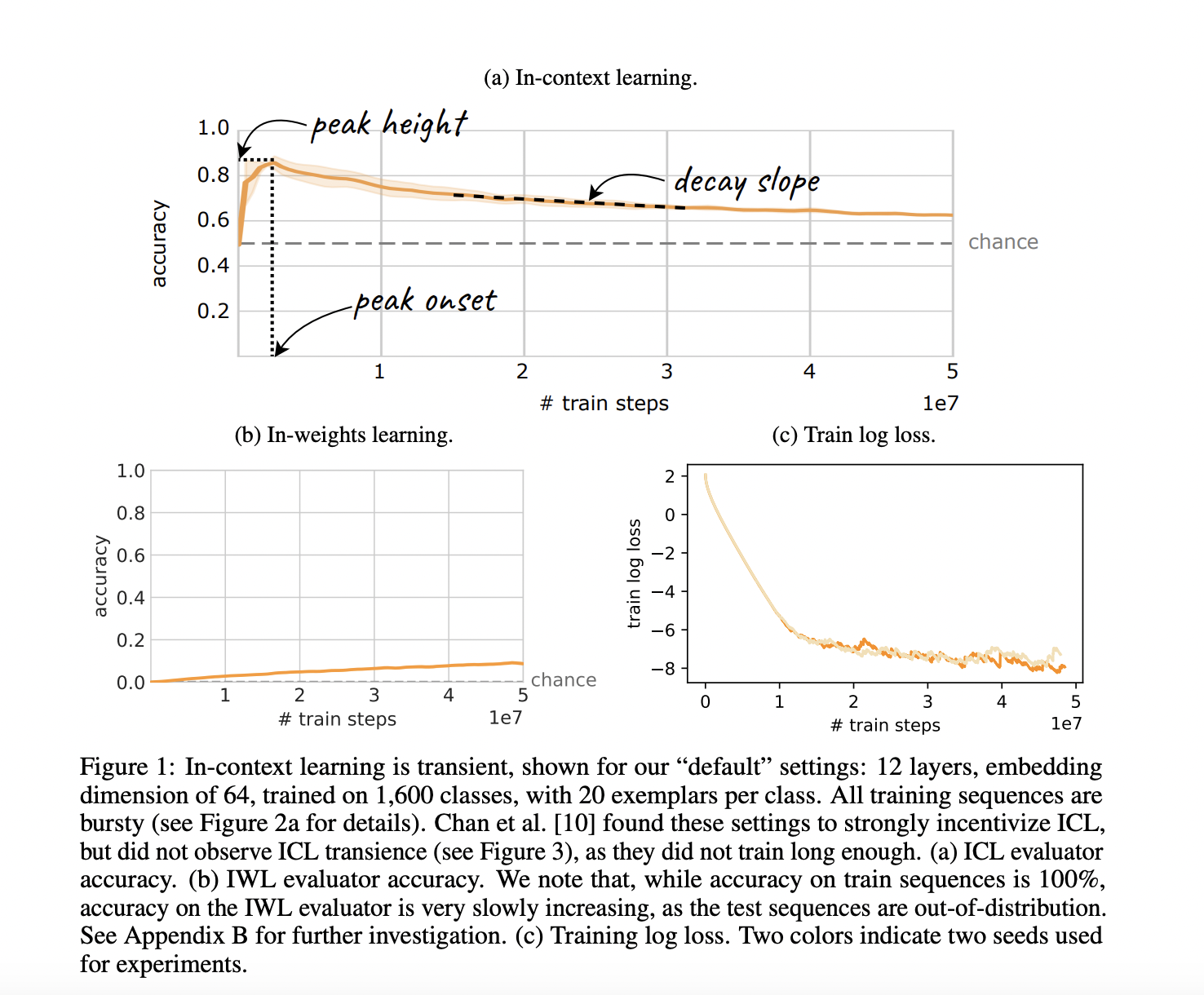
(c) Loss of training logs. Two hues signify the two experimental seeds.
Fundamentally, overtraining is predicated on a premise inherent in most recent investigations of ICL in LLMs, if not all of them: persistence. It is believed that a model will be kept during training as long as it has been taught enough for an ICL-dependent capability to arise, so long as the training loss keeps getting less. Here, the research team disproves the widespread belief that persistence exists. The research team do this by modifying a common image-based few-shot dataset, which enables us to assess ICL thoroughly in a controlled environment. The research team provides straightforward scenarios in which ICL appears and then vanishes as the loss of the model keeps declining.
To put it another way, even while ICL is widely recognized as an emerging phenomenon, the research team should also consider the possibility that it may only last temporarily (Figure 1). The research team discovered that transience happens for various model sizes, dataset sizes, and dataset kinds, although the research team also showed that certain attributes can delay transience. Generally speaking, networks that are trained irresponsibly for extended periods discover that ICL may vanish just as quickly as it appears, depriving models of the skills that people are coming to anticipate from contemporary AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Discover the vast possibilities of AI tools by visiting our website at
https://chatgptoai.com/ to delve deeper into this transformative technology.




Reviews
There are no reviews yet.