Harness the Potential of AI Tools with ChatGPT. Our blog offers comprehensive insights into the world of AI technology, showcasing the latest advancements and practical applications facilitated by ChatGPT’s intelligent capabilities.
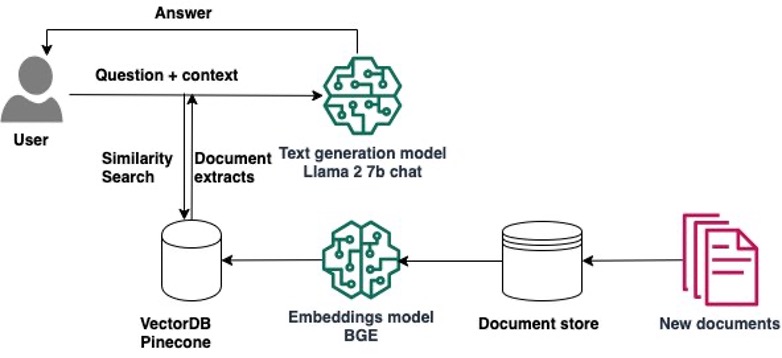
Retrieval Augmented Generation (RAG) allows you to provide a large language model (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. When using generative AI for question answering, RAG enables LLMs to answer questions with the most relevant, up-to-date information and optionally cite their data sources for verification.
A typical RAG solution for knowledge retrieval from documents uses an embeddings model to convert the data from the data sources to embeddings and stores these embeddings in a vector database. When a user asks a question, it searches the vector database and retrieves documents that are most similar to the user’s query. Next, it combines the retrieved documents and the user’s query in an augmented prompt that is sent to the LLM for text generation. There are two models in this implementation: the embeddings model and the LLM that generates the final response.
In this post, we demonstrate how to use Amazon SageMaker Studio to build a RAG question answering solution.
Using notebooks for RAG-based question answering
Implementing RAG typically entails experimenting with various embedding models, vector databases, text generation models, and prompts, while also debugging your code until you achieve a functional prototype. Amazon SageMaker offers managed Jupyter notebooks equipped with GPU instances, enabling you to rapidly experiment during this initial phase without spinning up additional infrastructure. There are two options for using notebooks in SageMaker. The first option is fast launch notebooks available through SageMaker Studio. In SageMaker Studio, the integrated development environment (IDE) purpose-built for ML, you can launch notebooks that run on different instance types and with different configurations, collaborate with colleagues, and access additional purpose-built features for machine learning (ML). The second option is using a SageMaker notebook instance, which is a fully managed ML compute instance running the Jupyter Notebook app.
In this post, we present a RAG solution that augments the model’s knowledge with additional data from external knowledge sources to provide more accurate responses specific to a custom domain. We use a single SageMaker Studio notebook running on an ml.g5.2xlarge instance (1 A10G GPU) and Llama 2 7b chat hf, the fine-tuned version of Llama 2 7b, which is optimized for dialog use cases from Hugging Face Hub. We use two AWS Media & Entertainment Blog posts as the sample external data, which we convert into embeddings with the BAAI/bge-small-en-v1.5 embeddings. We store the embeddings in Pinecone, a vector-based database that offers high-performance search and similarity matching. We also discuss how to transition from experimenting in the notebook to deploying your models to SageMaker endpoints for real-time inference when you complete your prototyping. The same approach can be used with different models and vector databases.
Solution overview
The following diagram illustrates the solution architecture.
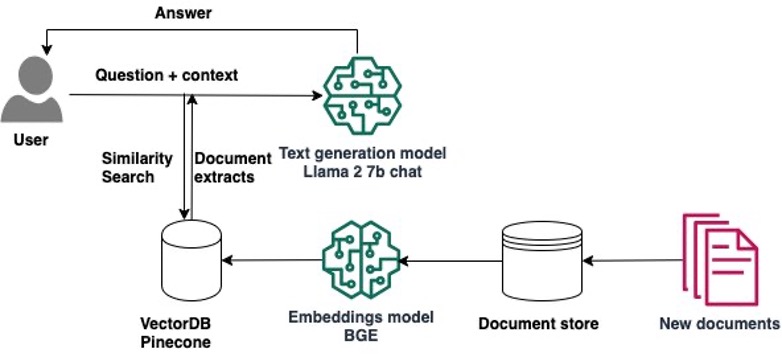
Implementing the solution consists of two high-level steps: developing the solution using SageMaker Studio notebooks, and deploying the models for inference.
Develop the solution using SageMaker Studio notebooks
Complete the following steps to start developing the solution:
- Load the Llama-2 7b chat model from Hugging Face Hub in the notebook.
- Create a PromptTemplate with LangChain and use it to create prompts for your use case.
- For 1–2 example prompts, add relevant static text from external documents as prompt context and assess if the quality of the responses improves.
- Assuming that the quality improves, implement the RAG question answering workflow:
- Gather the external documents that can help the model better answer the questions in your use case.
- Load the BGE embeddings model and use it to generate embeddings of these documents.
- Store these embeddings in a Pinecone index.
- When a user asks a question, perform a similarity search in Pinecone and add the content from the most similar documents to the prompt’s context.
Deploy the models to SageMaker for inference at scale
When you hit your performance goals, you can deploy the models to SageMaker to be used by generative AI applications:
- Deploy the Llama-2 7b chat model to a SageMaker real-time endpoint.
- Deploy the BAAI/bge-small-en-v1.5 embeddings model to a SageMaker real-time endpoint.
- Use the deployed models in your question answering generative AI applications.
In the following sections, we walk you through the steps of implementing this solution in SageMaker Studio notebooks.
Prerequisites
To follow the steps in this post, you need to have an AWS account and an AWS Identity and Access Management (IAM) role with permissions to create and access the solution resources. If you are new to AWS, see Create a standalone AWS account.
To use SageMaker Studio notebooks in your AWS account, you need a SageMaker domain with a user profile that has permissions to launch the SageMaker Studio app. If you are new to SageMaker Studio, the Quick Studio setup is the fastest way to get started. With a single click, SageMaker provisions the SageMaker domain with default presets, including setting up the user profile, IAM role, IAM authentication, and public internet access. The notebook for this post assumes an ml.g5.2xlarge instance type. To review or increase your quota, open the AWS Service Quotas console, choose AWS Services in the navigation pane, choose Amazon SageMaker, and refer to the value for Studio KernelGateway apps running on ml.g5.2xlarge instances.
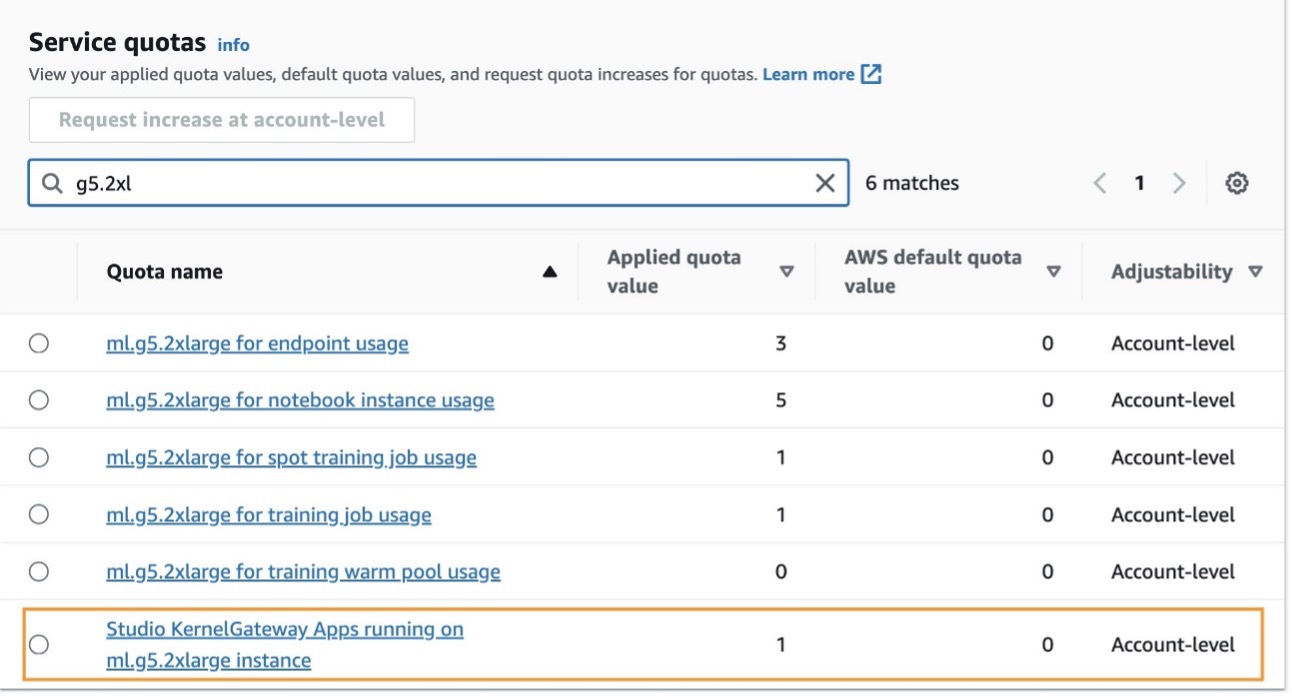
After confirming your quota limit, you need to complete the dependencies to use Llama 2 7b chat.
Llama 2 7b chat is available under the Llama 2 license. To access Llama 2 on Hugging Face, you need to complete a few steps first:
- Create a Hugging Face account if you don’t have one already.
- Complete the form “Request access to the next version of Llama” on the Meta website.
- Request access to Llama 2 7b chat on Hugging Face.
After you have been granted access, you can create a new access token to access models. To create an access token, navigate to the Settings page on the Hugging Face website.
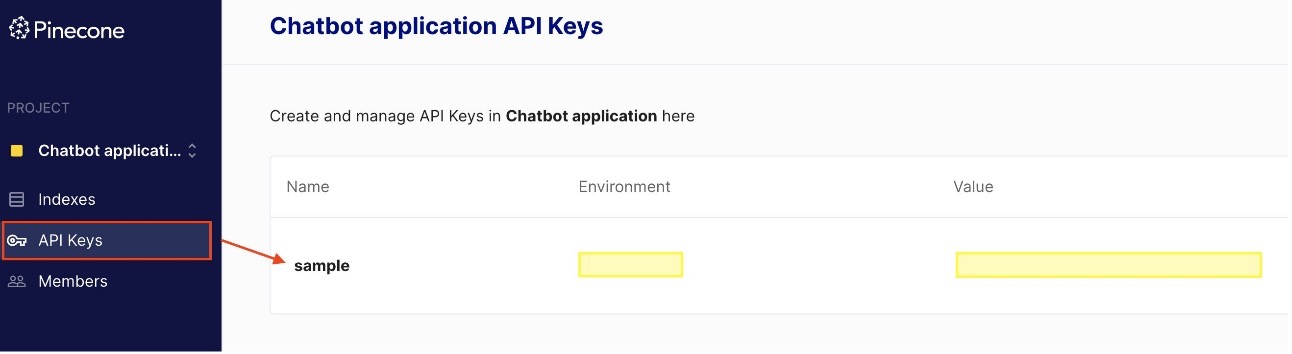
You need to have an account with Pinecone to use it as a vector database. Pinecone is available on AWS via the AWS Marketplace. The Pinecone website also offers the option to create a free account that comes with permissions to create a single index, which is sufficient for the purposes of this post. To retrieve your Pinecone keys, open the Pinecone console and choose API Keys.
Set up the notebook and environment
To follow the code in this post, open SageMaker Studio and clone the following GitHub repository. Next, open the notebook studio-local-gen-ai/rag/RAG-with-Llama-2-on-Studio.ipynb and choose the PyTorch 2.0.0 Python 3.10 GPU Optimized image, Python 3 kernel, and ml.g5.2xlarge as the instance type. If this is your first time using SageMaker Studio notebooks, refer to Create or Open an Amazon SageMaker Studio Notebook.
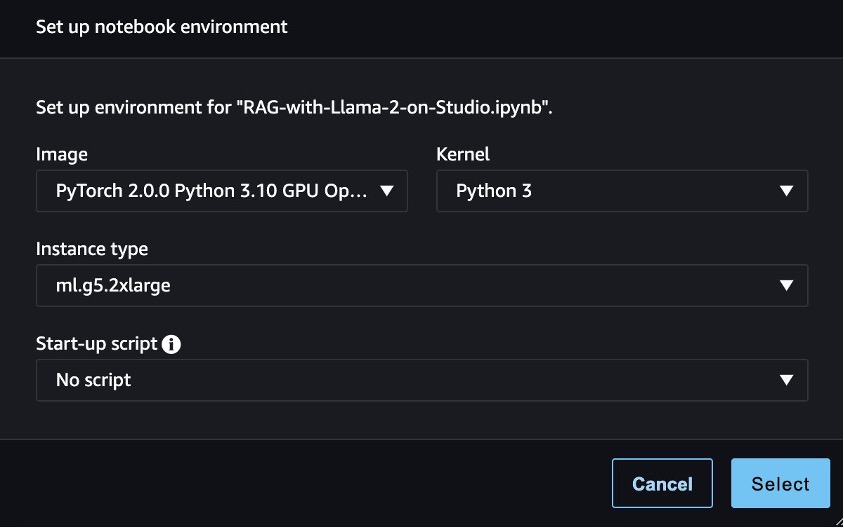
To set up the development environment, you need to install the necessary Python libraries, as demonstrated in the following code:
%%writefile requirements.txt
sagemaker>=2.175.0
transformers==4.33.0
accelerate==0.21.0
datasets==2.13.0
langchain==0.0.297
pypdf>=3.16.3
pinecone-client
sentence_transformers
safetensors>=0.3.3!pip install -U -r requirements.txtLoad the pre-trained model and tokenizer
After you have imported the required libraries, you can load the Llama-2 7b chat model along with its corresponding tokenizers from Hugging Face. These loaded model artifacts are stored in the local directory within SageMaker Studio. This enables you to swiftly reload them into memory whenever you need to resume your work at a different time.
import torch
from transformers import (
AutoTokenizer,
LlamaTokenizer,
LlamaForCausalLM,
GenerationConfig,
AutoModelForCausalLM
)
import transformers
tg_model_id = "meta-llama/Llama-2-7b-chat-hf" #the model id in Hugging Face
tg_model_path = f"./tg_model/{tg_model_id}" #the local directory where the model will be saved
tg_model = AutoModelForCausalLM.from_pretrained(tg_model_id, token=hf_access_token,do_sample=True, use_safetensors=True, device_map="auto", torch_dtype=torch.float16
tg_tokenizer = AutoTokenizer.from_pretrained(tg_model_id, token=hf_access_token)
tg_model.save_pretrained(save_directory=tg_model_path, from_pt=True)
tg_tokenizer.save_pretrained(save_directory=tg_model_path, from_pt=True)Ask a question that requires up-to-date information
You can now start using the model and ask questions. Llama-2 chat models expect the prompt to adhere to the following format:
<s>[INST] <<SYS>>
system_prompt
<<SYS>>
{{ user_message }} [/INST]You can use the PromptTemplate from LangChain to create a recipe based on the prompt format, so that you can easily create prompts going forward:
from langchain import PromptTemplate
template = """<s>[INST] <<SYS>>\nYou are an assistant for question-answering tasks. You are helpful and friendly. Use the following pieces of retrieved context to answer the query. If you don't know the answer, you just say I don't know. Use three sentences maximum and keep the answer concise.
<<SYS>>\n
{context}\n
{question} [/INST]
"""
prompt_template = PromptTemplate( template=template, input_variables=['context','question'] )Let’s ask the model a question that needs recent information from 2023. You can use LangChain and specifically the LLMChain type of chain and pass as parameters the LLM, the prompt template you created earlier, and the question:
question = "When can I visit the AWS M&E Customer Experience Center in New York City?"
tg_tokenizer.add_special_tokens( {"pad_token": "[PAD]"} )
tg_tokenizer.padding_side = "left"
tg_pipe = transformers.pipeline(task='text-generation', model=tg_model, tokenizer=tg_tokenizer, num_return_sequences=1, eos_token_id=tg_tokenizer.eos_token_id, pad_token_id=tg_tokenizer.eos_token_id, max_new_tokens=400, temperature=0.7)
from langchain.chains import LLMChain
from langchain.llms import HuggingFacePipeline
llm=HuggingFacePipeline(pipeline=tg_pipe, model_kwargs={'temperature':0.7})
llm_chain = LLMChain(llm=llm, prompt=prompt_template)
no_context_response = llm_chain.predict(context="", question=question)
print(no_context_response)We get the following generated answer:
Thank you for reaching out! The AWS M&E Customer Experience Center in New York City is currently closed for visits due to the COVID-19 pandemic. However, you can check their official website or social media accounts for any updates on when the center will reopen. In the meantime, you can explore their virtual tours and resources available online.
Improve the answer by adding context to the prompt
The answer we generated is not entirely true. Let’s see if we can improve it by providing some context. You can add an extract from the post AWS announces new M&E Customer Experience Center in New York, which includes updates on the topic from 2023:
context = """Media and entertainment (M&E) customers continue to face challenges in creating more content, more quickly, and distributing it to more endpoints than ever before in their quest to delight viewers globally. Amazon Web Services (AWS), along with AWS Partners, have showcased the rapid evolution of M&E solutions for years at industry events like the National Association of Broadcasters (NAB) Show and the International Broadcast Convention (IBC). Until now, AWS for M&E technology demonstrations were accessible in this way just a few weeks out of the year. Customers are more engaged than ever before; they want to have higher quality conversations regarding user experience and media tooling. These conversations are best supported by having an interconnected solution architecture for reference. Scheduling a visit of the M&E Customer Experience Center will be available starting November 13th, please send an email to AWS-MediaEnt-CXC@amazon.com."""Use the LLMChain again and pass the preceding text as context:
context_response = llm_chain.predict(context=context, question=question)
print(context_response)The new response answers the question with up-to-date information:
You can visit the AWS M&E Customer Experience Center in New York City starting from November 13th. Please send an email to AWS-MediaEnt-CXC@amazon.com to schedule a visit.
We have confirmed that by adding the right context, the model’s performance is improved. Now you can focus your efforts on finding and adding the right context for the question asked. In other words, implement RAG.
Implement RAG question answering with BGE embeddings and Pinecone
At this juncture, you must decide on the sources of information to enhance the model’s knowledge. These sources could be internal webpages or documents within your organization, or publicly available data sources. For the purposes of this post and for the sake of simplicity, we have chosen two AWS Blog posts published in 2023:
These posts are already available as PDF documents in the data project directory in SageMaker Studio for quick access. To divide the documents into manageable chunks, you can employ the RecursiveCharacterTextSplitter method from LangChain:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFDirectoryLoader
loader = PyPDFDirectoryLoader("./data/")
documents = loader.load()
text_splitter=RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=5
)
docs = text_splitter.split_documents(documents)Next, use the BGE embeddings model bge-small-en created by the Beijing Academy of Artificial Intelligence (BAAI) that is available on Hugging Face to generate the embeddings of these chunks. Download and save the model in the local directory in Studio. We use fp32 so that it can run on the instance’s CPU.
em_model_name = "BAAI/bge-small-en"
em_model_path = f"./em-model"
from transformers import AutoModel
# Load model from HuggingFace Hub
em_model = AutoModel.from_pretrained(em_model_name,torch_dtype=torch.float32)
em_tokenizer = AutoTokenizer.from_pretrained(em_model_name,device="cuda")
# save model to disk
em_tokenizer.save_pretrained(save_directory=f"{em_model_path}/model",from_pt=True)
em_model.save_pretrained(save_directory=f"{em_model_path}/model",from_pt=True)
em_model.eval()Use the following code to create an embedding_generator function, which takes the document chunks as input and generates the embeddings using the BGE model:
# Tokenize sentences
def tokenize_text(_input, device):
return em_tokenizer(
[_input],
padding=True,
truncation=True,
return_tensors="pt"
).to(device)
# Run embedding task as a function with model and text sentences as input
def embedding_generator(_input, normalize=True):
# Compute token embeddings
with torch.no_grad():
embedded_output = em_model(
**tokenize_text(
_input,
em_model.device
)
)
sentence_embeddings = embedded_output[0][:, 0]
# normalize embeddings
if normalize:
sentence_embeddings = torch.nn.functional.normalize(
sentence_embeddings,
p=2,
dim=1
)
return sentence_embeddings[0, :].tolist()
sample_sentence_embedding = embedding_generator(docs[0].page_content)
print(f"Embedding size of the document --->", len(sample_sentence_embedding))In this post, we demonstrate a RAG workflow using Pinecone, a managed, cloud-native vector database that also offers an API for similarity search. You are free to rewrite the following code to use your preferred vector database.
We initialize a Pinecone python client and create a new vector search index using the embedding model’s output length. We use LangChain’s built-in Pinecone class to ingest the embeddings we created in the previous step. It needs three parameters: the documents to ingest, the embeddings generator function, and the name of the Pinecone index.
import pinecone
pinecone.init(
api_key = os.environ["PINECONE_API_KEY"],
environment = os.environ["PINECONE_ENV"]
)
#check if index already exists, if not we create it
index_name = "rag-index"
if index_name not in pinecone.list_indexes():
pinecone.create_index(
name=index_name,
dimension=len(sample_sentence_embedding), ## 384 for bge-small-en
metric="cosine"
)
#insert the embeddings
from langchain.vectorstores import Pinecone
vector_store = Pinecone.from_documents(
docs,
embedding_generator,
index_name=index_name
)With the Llama-2 7B chat model loaded into memory and the embeddings integrated into the Pinecone index, you can now combine these elements to enhance Llama 2’s responses for our question-answering use case. To achieve this, you can employ the LangChain RetrievalQA, which augments the initial prompt with the most similar documents from the vector store. By setting return_source_documents=True, you gain visibility into the exact documents used to generate the answer as part of the response, allowing you to verify the accuracy of the answer.
from langchain.chains import RetrievalQA
import textwrap
#helper method to improve the readability of the response
def print_response(llm_response):
temp = [textwrap.fill(line, width=100) for line in llm_response['result'].split('\n')]
response="\n".join(temp)
print(f"{llm_response['query']}\n \n{response}'\n \n Source Documents:")
for source in llm_response["source_documents"]:
print(source.metadata)
llm_qa_chain = RetrievalQA.from_chain_type(
llm=llm, #the Llama-2 7b chat model
chain_type="stuff",
retriever=vector_store.as_retriever(search_kwargs={"k": 2}), # perform similarity search in Pinecone
return_source_documents=True, #show the documents that were used to answer the question
chain_type_kwargs={"prompt": prompt_template}
)
print_response(llm_qa_chain(question))We get the following answer:
Q: When can I visit the AWS M&E Customer Experience Center in New York City?
A: I’m happy to help! According to the context, the AWS M&E Customer Experience Center in New York City will be available for visits starting on November 13th. You can send an email to AWS-MediaEnt-CXC@amazon.com to schedule a visit.’
Source Documents:
{‘page’: 4.0, ‘source’: ‘data/AWS announces new M&E Customer Experience Center in New York City _ AWS for M&E Blog.pdf’}
{‘page’: 2.0, ‘source’: ‘data/AWS announces new M&E Customer Experience Center in New York City _ AWS for M&E Blog.pdf’}
Let’s try a different question:
question2=" How many awards have AWS Media Services won in 2023?"
print_response(llm_qa_chain(question2))We get the following answer:
Q: How many awards have AWS Media Services won in 2023?
A: According to the blog post, AWS Media Services have won five industry awards in 2023.’
Source Documents:
{‘page’: 0.0, ‘source’: ‘data/AWS Media Services awarded industry accolades _ AWS for M&E Blog.pdf’}
{‘page’: 1.0, ‘source’: ‘data/AWS Media Services awarded industry accolades _ AWS for M&E Blog.pdf’}
After you have established a sufficient level of confidence, you can deploy the models to SageMaker endpoints for real-time inference. These endpoints are fully managed and offer support for auto scaling.
SageMaker offers large model inference using Large Model Inference containers (LMIs), which we can utilize to deploy our models. These containers come equipped with pre-installed open source libraries like DeepSpeed, facilitating the implementation of performance-enhancing techniques such as tensor parallelism during inference. Additionally, they use DJLServing as a pre-built integrated model server. DJLServing is a high-performance, universal model-serving solution that offers support for dynamic batching and worker auto scaling, thereby increasing throughput.
In our approach, we use the SageMaker LMI with DJLServing and DeepSpeed Inference to deploy the Llama-2-chat 7b and BGE models to SageMaker endpoints running on ml.g5.2xlarge instances, enabling real-time inference. If you want to follow these steps yourself, refer to the accompanying notebook for detailed instructions.
You will require two ml.g5.2xlarge instances for deployment. To review or increase your quota, open the AWS Service Quotas console, choose AWS Services in the navigation pane, choose Amazon SageMaker, and refer to the value for ml.g5.2xlarge for endpoint usage.
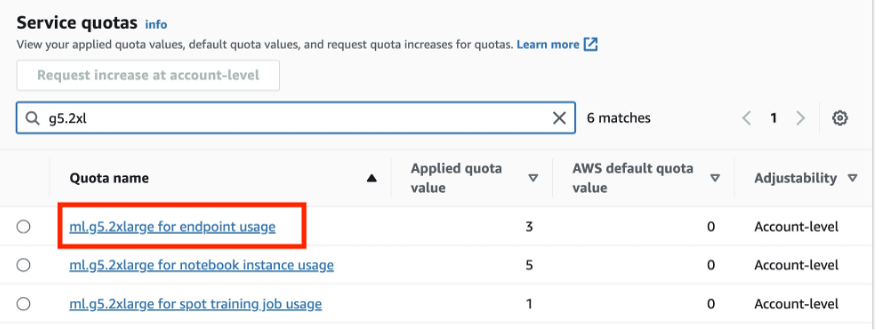
The following steps outline the process of deploying custom models for the RAG workflow on a SageMaker endpoint:
- Deploy the Llama-2 7b chat model to a SageMaker real-time endpoint running on an
ml.g5.2xlargeinstance for fast text generation. - Deploy the BAAI/bge-small-en-v1.5 embeddings model to a SageMaker real-time endpoint running on an
ml.g5.2xlargeinstance. Alternatively, you can deploy your own embedding model. - Ask a question and use the LangChain RetrievalQA to augment the prompt with the most similar documents from Pinecone, this time using the model deployed in the SageMaker real-time endpoint:
# convert your local LLM into SageMaker endpoint LLM
llm_sm_ep = SagemakerEndpoint(
endpoint_name=tg_sm_model.endpoint_name, # <--- Your text-gen model endpoint name
region_name=region,
model_kwargs={
"temperature": 0.05,
"max_new_tokens": 512
},
content_handler=content_handler,
)
llm_qa_smep_chain = RetrievalQA.from_chain_type(
llm=llm_sm_ep, # <--- This uses SageMaker Endpoint model for inference
chain_type="stuff",
retriever=vector_store.as_retriever(search_kwargs={"k": 2}),
return_source_documents=True,
chain_type_kwargs={"prompt": prompt_template}
)- Use LangChain to verify that the SageMaker endpoint with the embedding model works as expected so that it can be used for future document ingestion:
response_model = smr_client.invoke_endpoint(
EndpointName=em_sm_model.endpoint_name, <--- Your embedding model endpoint name
Body=json.dumps({
"text": "This is a sample text"
}),
ContentType="application/json",
)
outputs = json.loads(response_model["Body"].read().decode("utf8"))['outputs']Clean up
Complete the following steps to clean up your resources:
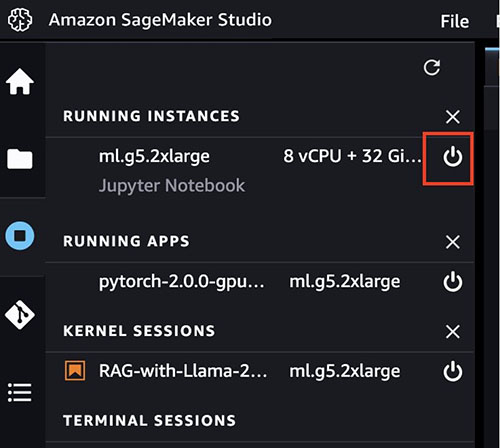
- When you have finished working in your SageMaker Studio notebook, make sure you shut down the
ml.g5.2xlargeinstance to avoid any charges by choosing the stop icon. You can also set up lifecycle configuration scripts to automatically shut down resources when they are not used.
- If you deployed the models to SageMaker endpoints, run the following code at the end of the notebook to delete the endpoints:
#delete your text generation endpoint
sm_client.delete_endpoint(
EndpointName=tg_sm_model.endpoint_name
)
# delete your text embedding endpoint
sm_client.delete_endpoint(
EndpointName=em_sm_model.endpoint_name
)- Finally, run the following line to delete the Pinecone index:
pinecone.delete_index(index_name)Conclusion
SageMaker notebooks provide a straightforward way to kickstart your journey with Retrieval Augmented Generation. They allow you to experiment interactively with various models, configurations, and questions without spinning up additional infrastructure. In this post, we showed how to enhance the performance of Llama 2 7b chat in a question answering use case using LangChain, the BGE embeddings model, and Pinecone. To get started, launch SageMaker Studio and run the notebook available in the following GitHub repo. Please share your thoughts in the comments section!
About the authors
 Anastasia Tzeveleka is a Machine Learning and AI Specialist Solutions Architect at AWS. She works with customers in EMEA and helps them architect machine learning solutions at scale using AWS services. She has worked on projects in different domains including Natural Language Processing (NLP), MLOps and Low Code No Code tools.
Anastasia Tzeveleka is a Machine Learning and AI Specialist Solutions Architect at AWS. She works with customers in EMEA and helps them architect machine learning solutions at scale using AWS services. She has worked on projects in different domains including Natural Language Processing (NLP), MLOps and Low Code No Code tools.
 Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes. In his free time, he enjoys playing chess and traveling.
Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes. In his free time, he enjoys playing chess and traveling.
Discover the vast possibilities of AI tools by visiting our website at
https://chatgptoai.com/ to delve deeper into this transformative technology.



Reviews
There are no reviews yet.